
导读
以Sora、DALL-E、ChatGPT 为代表的生成式人工智能席卷全球,正广泛应用于知识问答、视频生成等多个领域,成为多个重要行业的创新引擎。生成式人工智能作为新一代国家人工智能基础设施的关键要素,已成为世界各国战略资源和软实力竞争的焦点。与此同时,生成式人工智能技术的成熟与广泛使用也带来生成伪造信息等新型安全风险,导致安全事件频发。不法分子利用深度伪造技术(Deepfake)生成以假乱真的有害视频、图像等视觉内容,这些内容在互联网广泛传播,引发了诸如电信诈骗、国家领导人诋毁、色情视频伪造、以及人脸认证系统欺骗等安全问题,牵动国家安全与社会稳定。
古语云“百闻不如一见”,相较于文本和音频,视觉信息通常更为直观且具有更强的说服力。然而“眼见不一定为实”,基于深度合成技术伪造的图像和视频往往具有迷惑性。例如,2022年俄乌战争中,乌克兰总统泽连斯基呼吁乌克兰士兵投降的伪造视频在网络上疯传;2024年诈骗分子利用深度伪造技术在视频会议中冒充英国某公司高层管理者的形象和声音,骗取了中国香港某公司近2亿港元;2024年知名美国女星泰勒斯威夫特的伪造色情视频在网络上引发数百万人热议。这些案例均凸显了深度合成技术对个人、社会以及国家安全的潜在威胁。
为了有效应对这些威胁,2022年国家网信办、工信部和公安部联合发布法规《互联网信息服务深度合成管理规定》,针对人脸生成、替换、编辑、操控等深度合成技术提出规范性要求。2023年,国家网信办等七部门颁布《生成式人工智能服务管理暂行办法》,进一步明确了对生成式人工智能服务的“分类”和“分级”监管,并要求深度伪造服务的提供者必须对图片、视频等生成内容进行标识。然而,深度伪造监管法规的落地依赖精准通用的深度伪造检测技术。
随着深度伪造技术的持续演进,图像和视频的伪造检测变得愈发具有挑战性。图像和视频数据分布差异、伪造算法复杂多样导致现有伪造检测算法存在检测精度低、泛化性不足的问题。此外,面对不断演进的生成式人工智能技术、复杂多变的现实检测场景,以及多样化的数据攻击手段,现有伪造检测方法安全防护能力薄弱。为了应对这些挑战,浙江大学区块链与数据安全全国重点实验室大模型数据安全团队围绕深度伪造检测展开关键技术攻关,发布主要聚焦视觉深度伪造检测领域,推出视觉深度伪造检测平台DFscan场景视觉伪造技术的威胁。
一、深度伪造视频检测平台DFscan
DFscan区块链与数据安全全国重点实验室大模型数据安全团队开发的视觉伪造检测平台。平台从促进生成式人工智能的合法化应用和健康化发展出发,专注于图像/视频深度伪造内容的风险管控,可应用于AI电诈视频甄别、人脸识别系统防护、重点人物伪造视频监管、媒体内容合规性检测等场景。同时,检测平台支持伪造区域定位、伪造特征可视化和伪造方法溯源等细粒度检测功能,并能够生成多维可视化的检测报告。
DFscan平台介绍
DFscan向开放世界不同场景下的通用检测平台,以数据底座为支撑、以自研算法为驱动、以检测精度为核心,搭建了图像/视频伪造检测子平台与检测算法评估子平台。
图像/视频伪造检测子平台的核心功能是检测输入的图像/视频是真实拍摄还是由人工智能模型生成。与已有深度伪造检测技术相比,DFscan型评估技术,聚焦现有算法泛化性差、鲁棒性不足等问题,在多个不同数据域上均取得检测精度提升。检测算法评估子平台的核心功能是对输入的视频/图像伪造检测算法的各项检测能力进行评估。为制定统一、多维的评估标准,评估平台构建大量评估数据集,涵盖六大主流视频深度伪造类型。同时,平台构建了对比算法库,配置大量开源检测算法作为评测基准算法,通过多维度指标测评,生成全方位性能评估报告。
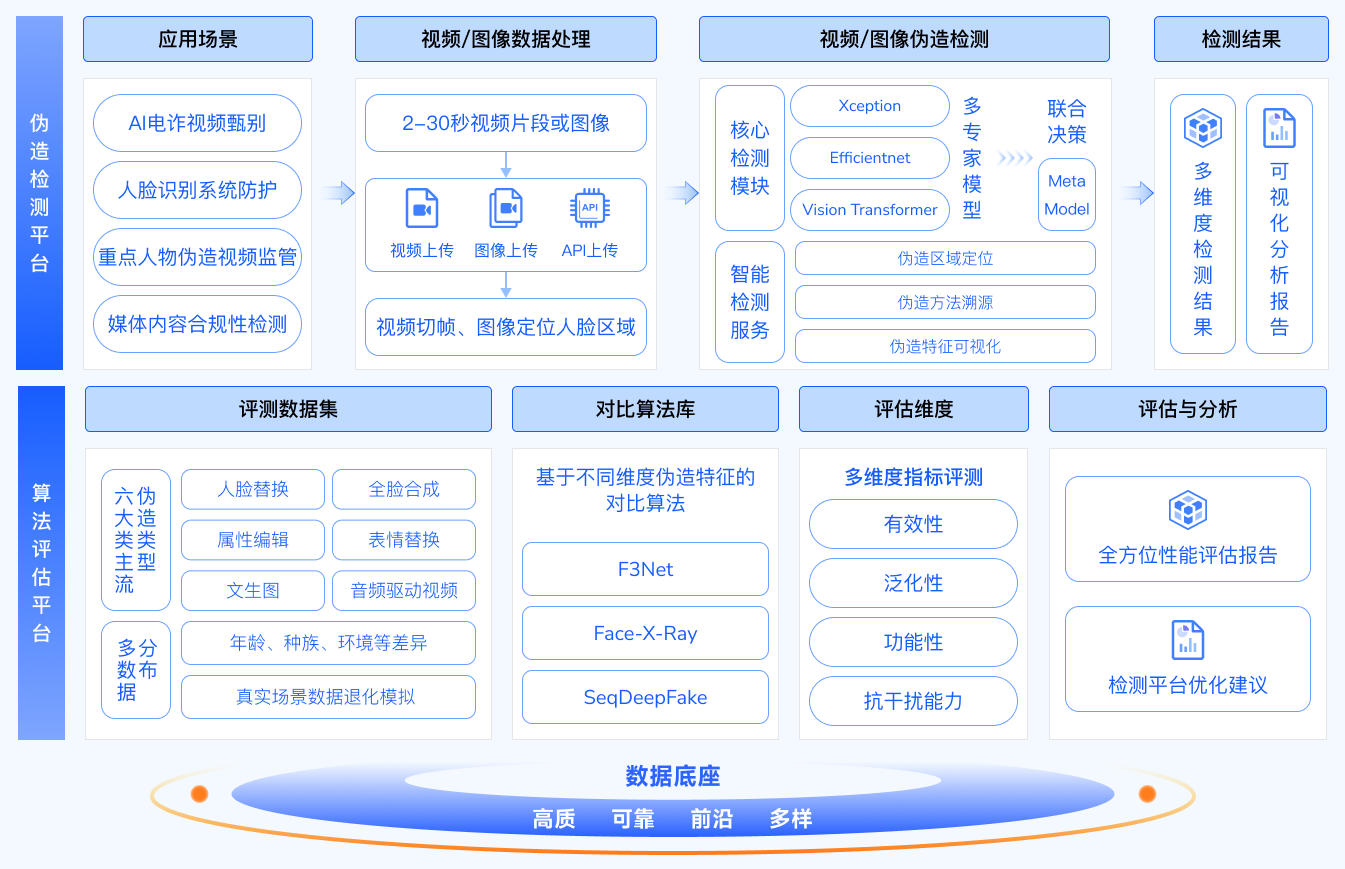
平台架构图
DFscan功能性子平台和大规模数据底座构成,如上图所示。两大子平台在技术层面相互促进,而数据集底座为两大子平台的构建提供了基础与支撑。它们共同构成一个完整且高效的系统,为相关研究和应用提供了有力的支持。下图展示了DFscan用户可以通过网页上传待检测视频或者直接调用API方式使用本平台检测功能。待检测视频经过切帧和人脸区域裁剪等预处理操作后,被输入至多个不同类别的专家模型进行伪造检测,其中每类专家模型又包含多个相同结构的子模型。决策阶段给同一类专家模型的不同子模型赋予不同权重,并通过加权相加聚合各子模型的输出结果,最后采用共识决策方法融合多类专家模型的置信度分数。平台通过错误率(EER)确定系统最佳判定阈值,将最终检测置信度与阈值比较,得到真伪判别结果。
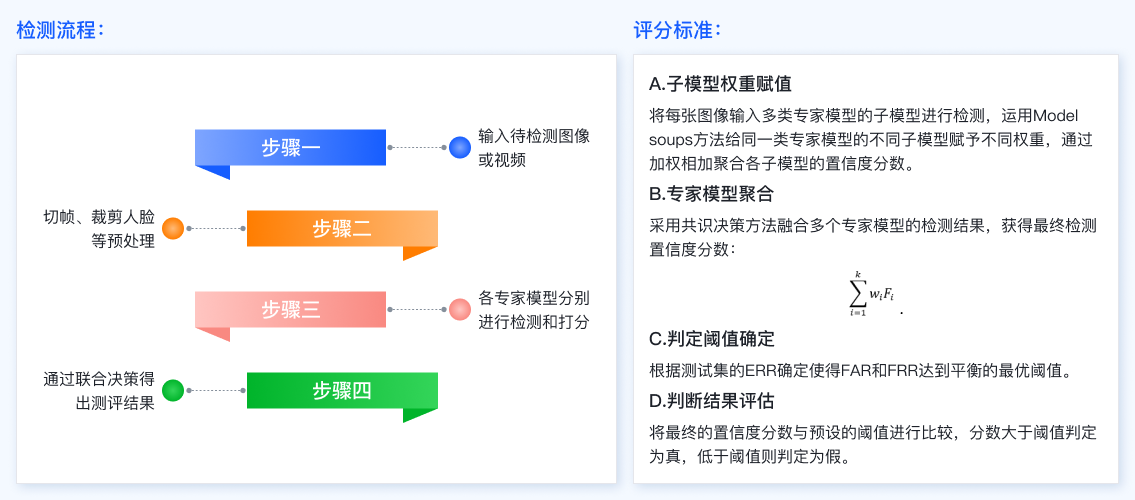
DFscan检测流程与评分标准
DFscan特色优势
DFscan平台注重自我迭代与最新深度伪造技术研究,在数据算法积累、算法评估、核心检测能力与多功能服务方面具备显著优势。
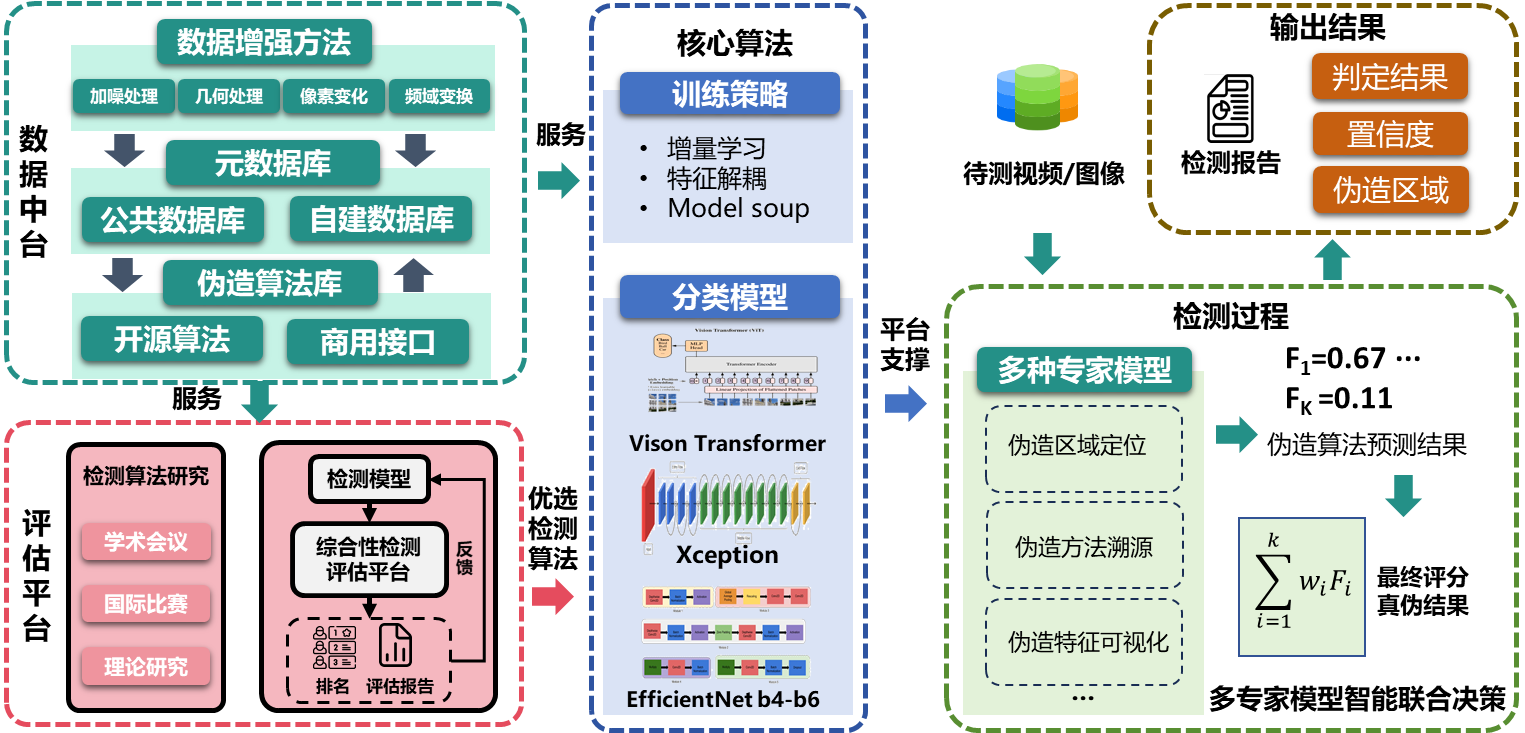
平台功能展示
【数据、算法、成果及项目广域积累】
团队基于知识+数据驱动的模式构建视觉深度伪造检测平台,平台核心在于高质量数据和优秀算法的双重积累。DFscan广泛汇集代表性、多样化开源数据,同时部署大量伪造算法并构建规模化自建数据集,用于支撑模型高效训练,提升模型对各种深度伪造技术的检测能力。同时,通过辨识伪造内容和真实内容的表征差异性、挖掘不同生成途径的深度伪造内容一致性特征,从而准确地识别出潜在的伪造图像/视频。
1.大规模数据库及场景化数据增强
DFscan平台收集了15个公开的伪造和真实数据集,并部署了20+种常见伪造算法的批量生成脚本,构建了千万级的自建图像/视频伪造数据库。在数据库构建时,我们考虑了差异化人种、性别、年龄、真伪片段混合、拍摄角度、光照等属性差异。此外,平台针对现实世界检测任务设计了场景化数据增强体系,重点围绕模型的鲁棒性和泛化性进行拟真化提升,以推进DFscan平台实战性能。数据增强包含旋转、加噪、压缩、滤波、亮度饱和度对比度调整等真实场景模拟技术,以此提升检测器的鲁棒性。同时,对部分图像使用重构和对抗攻击算法进行特殊处理,进一步增强检测器对不同攻击手段的检测能力,以应对恶意的逃逸攻击。
2.多元化算法底座
DFscan平台伪造算法底座除了人脸换脸、表情驱动、属性编辑、全脸合成等四类基础伪造算法外,还涵盖了文本生成图像/视频和音频驱动图像伪造算法。在检测算法方面,平台部署了12+种典型的开源伪造检测算法,用于评估和比较检测能力。其中,包括真伪判断的视频级、整图级和人脸级常规伪造检测算法10余种,以及具有图像伪造区域定位和视频伪造片段判别功能的特殊伪造检测算法2种。这种丰富的检测算法和评估结果积累,为平台的核心检测能力的建设奠定了坚实的基础。
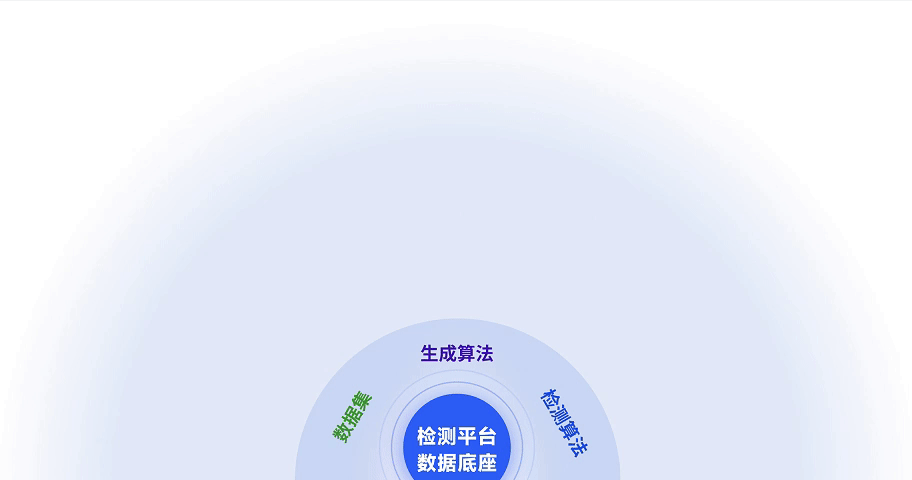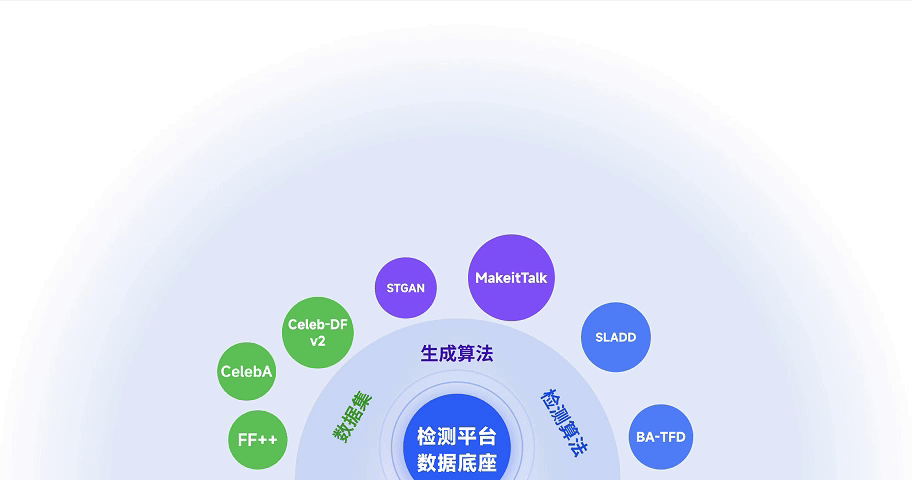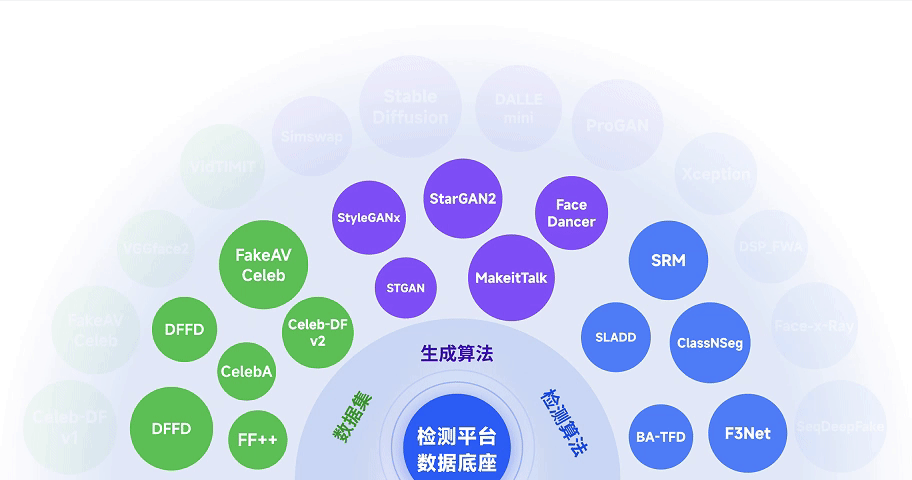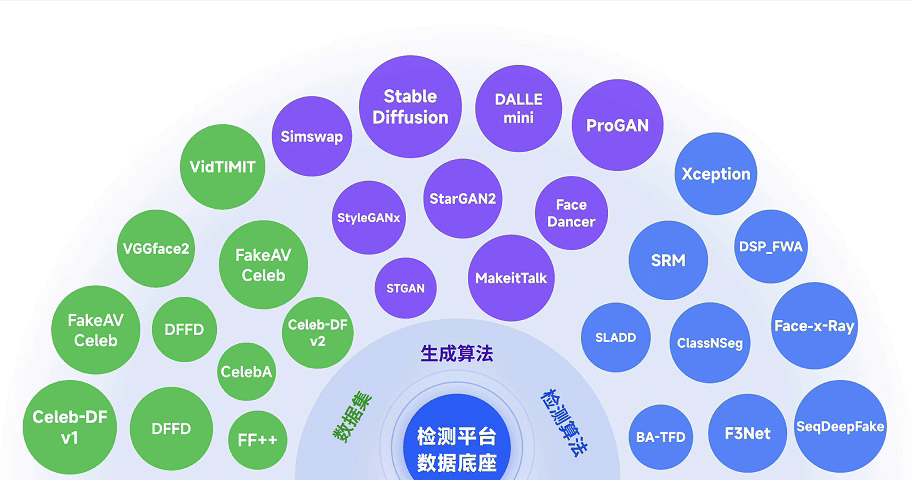
数据与算法底座
3.成果和项目积累
DFscan团队目前在国内外顶级会议和期刊上发表了40+篇论文,获第三届中国人工智能大赛音视频合成挑战赛A级(一等奖)证书。同时,平台与国家部门、互联网头部企业开展广泛合作,包括北京网安总队、嘉善公安、腾讯QQ等。
【核心检测技术构建】
深度伪造技术的日益更新和迭代导致了现有深度伪造检测技术的泛化性受到严重挑战,同时,单一模型对数据中的噪声和异常值比较敏感,可能导致过拟合或者欠拟合,容易出现预测偏差。针对以上问题,本平台研发高泛化性检测模型和换脸场景高精度检测模型,并着力推进重点人物伪造检测和检测能力跨伪造算法迁移研究。
1.高泛化性检测模型
由于不同类型伪造模型生成的伪造样本呈现出多样化的伪造特征,这些特征既具有特异性也表现出一定的通用性。为了构建一个具备高度泛化能力的通用检测模型,本平台创新性地设计了基于互信息最大化的伪造特征解耦方法。该方法旨在将全局的伪造特征细化为多种不同且互不重叠的伪造痕迹特征。随后,筛选出对检测任务起主导作用的特征,以及那些对构建通用模型尤为关键的通用伪造痕迹特征。这一系列的策略和方法旨在提高检测模型的准确性和泛化能力,以应对复杂多变的伪造样本。
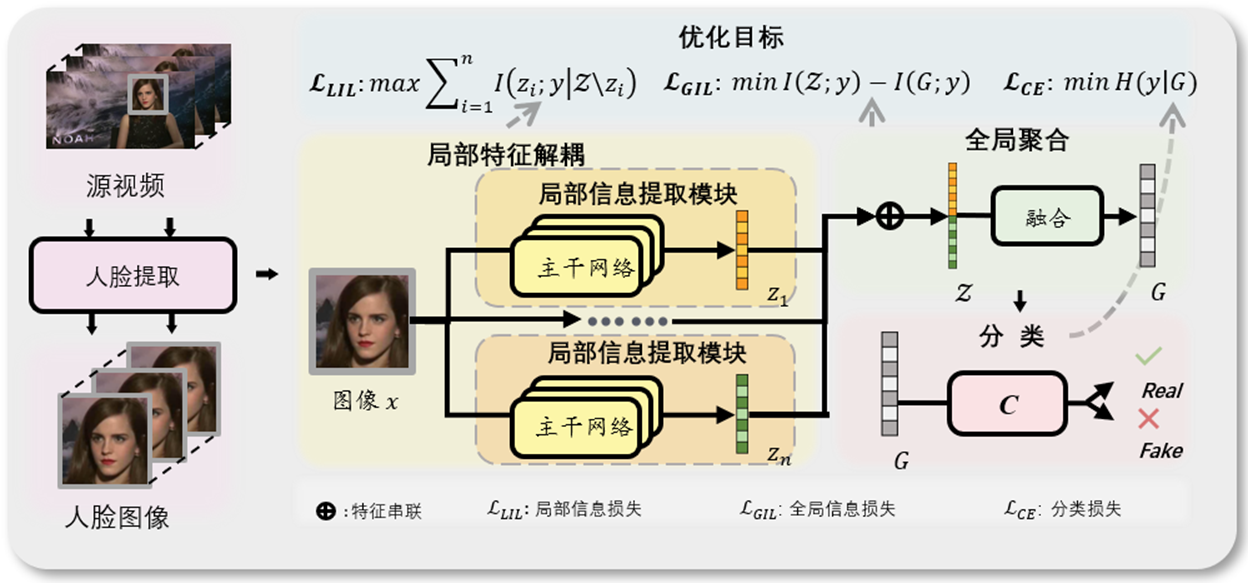
基于互信息最大化的伪造特征解耦方法
2.换脸场景高精度检测模型
平台对深度伪造中人脸替换高危场景进行研究,部署10余种开源检测模型,提出现有换脸检测算法普遍存在跨伪造算法检测精度低的问题。团队设计了基于定位和验证的双流检测模型,通过三个功能模块来协作处理多模态和多尺度特征,并利用定位的伪造区域引导模型感知潜在的换脸区域,强化模型对换脸数据的检测能力。同时,为了解决数据库中海量换脸图像缺乏伪造区域标注的问题,我们提出了基于半监督学习的伪造区域估计策略。
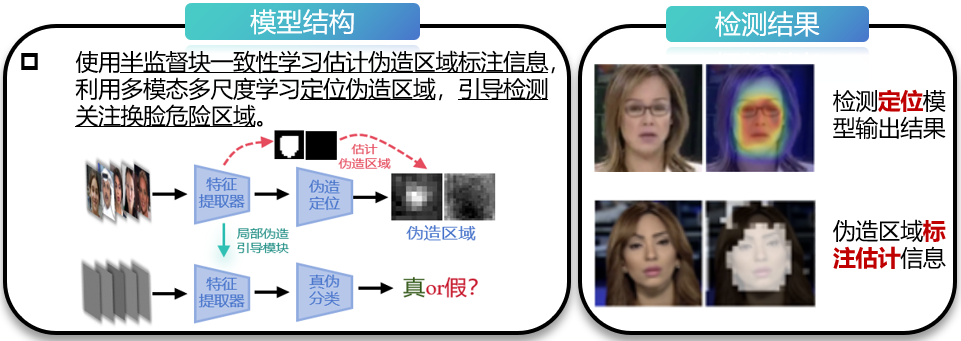
基于定位和验证的双流检测模型
3.重点人物的伪造检测
现有伪造检测算法普遍存在跨数据集检测性能不理想的问题,而近年来针对重点人物的伪造视频在社交媒体中的传播逐渐增多,亟需针对重点人物的高准确率、高泛化的伪造检测模型。研究发现,虽然现有的伪造算法生成的视频逼真度较高,已经能够很大程度上欺骗人眼的判断,但是深度神经网络仍能通过提取特征加以区分。这一点在身份特征上尤其如此,实验发现,利用人脸识别场景中常用的身份特征提取网络,真实人脸和伪造人脸提取的身份特征会分布于不同的特征空间位置。基于这一发现,团队实现了基于身份先验的重点人物伪造检测方法,通过引入重点人物真实图像作为先验信息,构建了针对重点人物伪造视频场景的伪造检测框架,大大提高了该场景下的检测准确率和跨域能力。
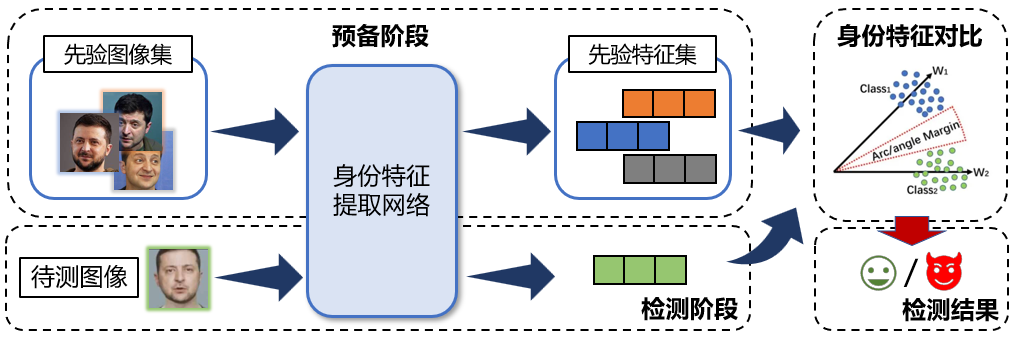
基于身份先验信息的重点人物检测方法
4.检测能力跨伪造算法迁移
平台致力于对新兴的深度伪造技术进行深入研究,并实现检测模型的持续更新迭代。然而,在实际应用中,我们面临着全新伪造样本数据不均衡和模型迭代时发生灾难性遗忘等挑战。这些问题使得现有检测模型难以对少量全新伪造样本进行有效学习。如果模型直接对现有数据进行学习,不仅会由于数据量少而导致模型无法提取到有效的特征信息,更可能引发灾难性遗忘,从而损失现有的检测能力。为了解决这些问题,团队提出采用基于域自适应的增量学习策略来推动平台的更新迭代。该策略通过有监督的对比学习,能够充分利用新旧数据之间的关联性,使模型对新任务进行有效学习。同时,结合多角度知识蒸馏策略和困难样本回放技术,进一步提升了模型的泛化能力和稳定性,有效缓解了灾难性遗忘的问题。通过实施这一策略,我们期望能够实现对深度伪造技术的持续跟踪和有效应对,同时不断优化和完善检测模型,提升其在现实场景中的应用效果。
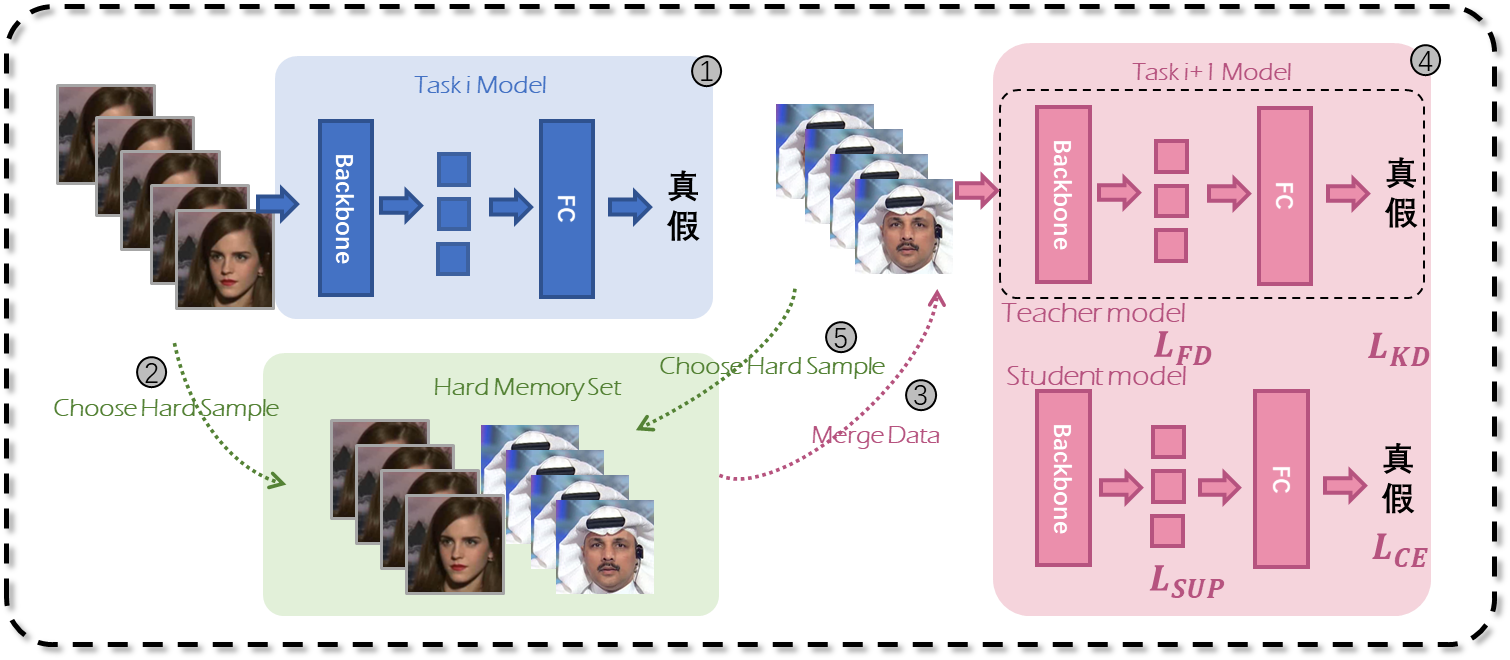
基于域自适应的伪造检测增量学习框架
【多功能检测服务】
DFscan立足于现实场景的检测需求,依靠团队在数据、算法、工程上的广域积累,为用户提供可信精准、功能丰富、透明易用的检测服务。平台支持单条或批量的图像和视频数据检测功能,用户只需一键上传待检测数据,等待数秒,平台即可返会检测报告,不仅给出判定结果,而且详细说明各专家模型给出的置信度分数。对于视频数据,报告会进一步给出细粒度片段的判定结果和平均置信度分数。后续平台会陆续上线伪造区域定位、伪造方法溯源等细粒度判定功能。DFscan平台通过多专家模型、多检测维度和多可视化方法,使得判定结果更为精准清晰,从而提升用户对于平台的体验感受和决策信任度。
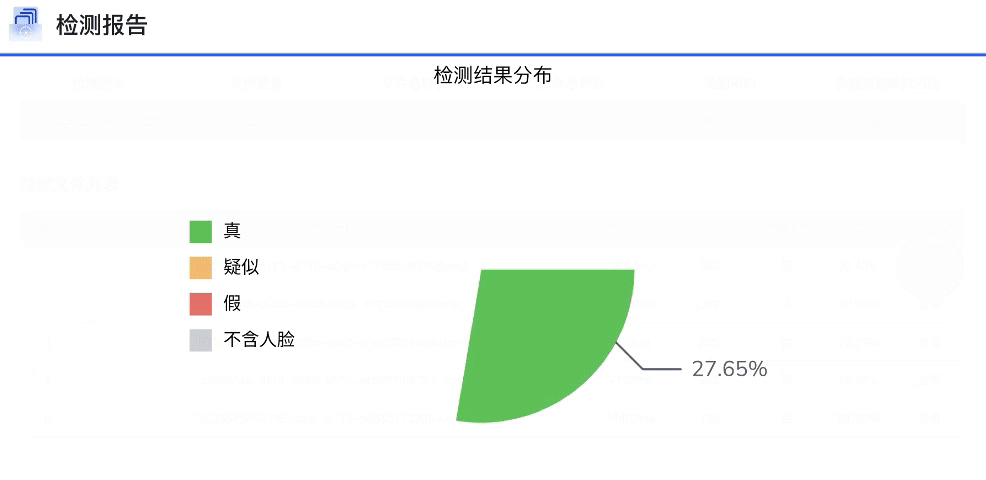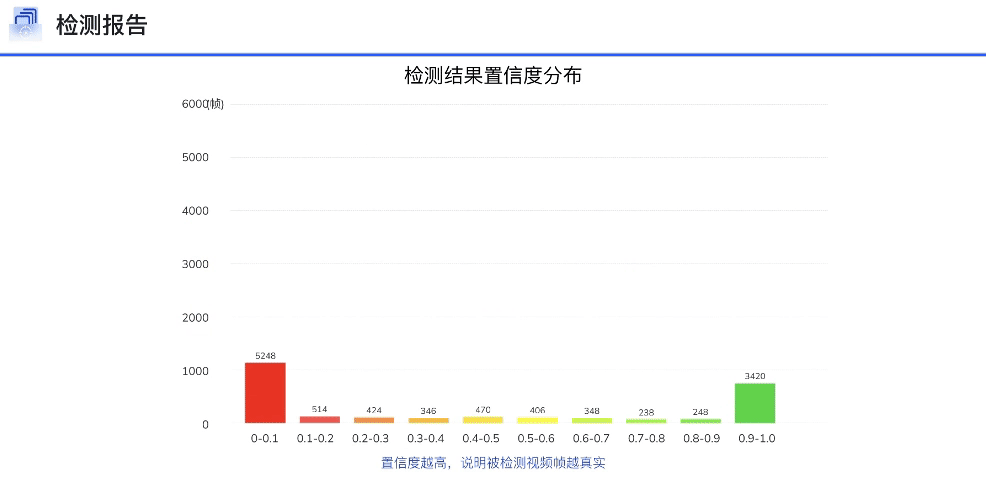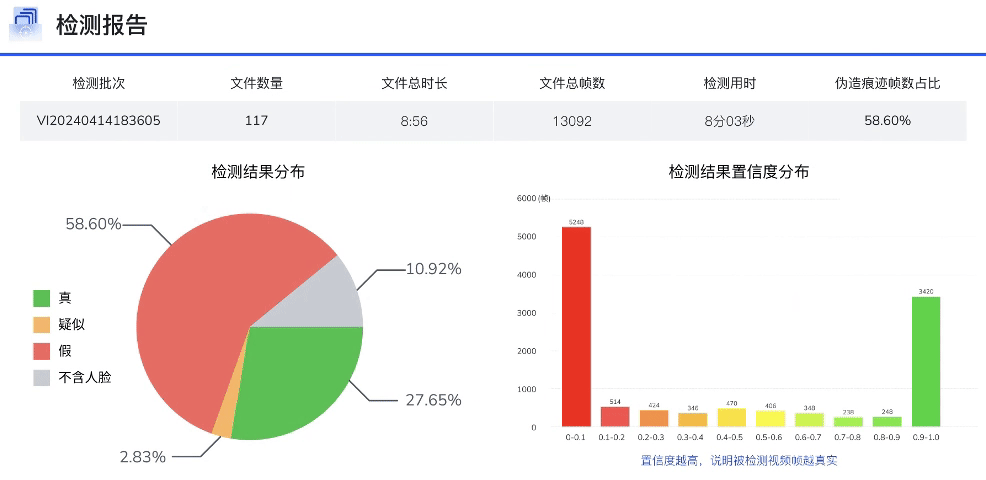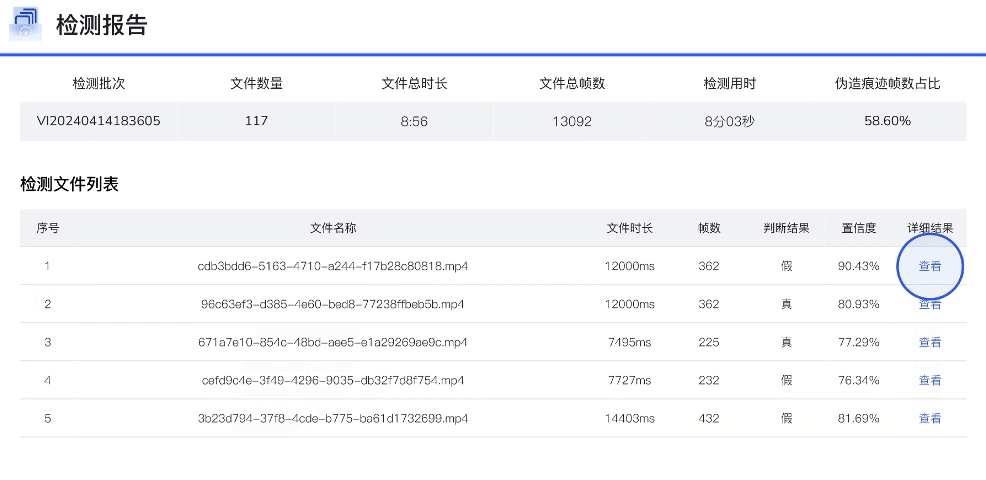
DFscan平台视频批量检测效果展示
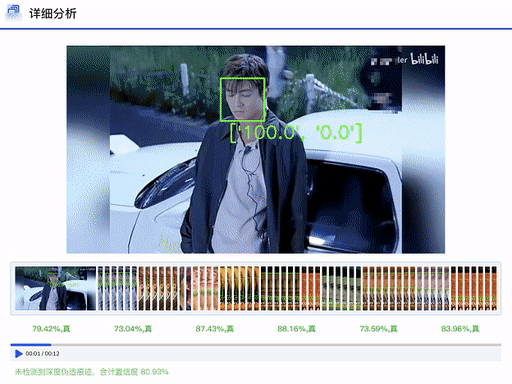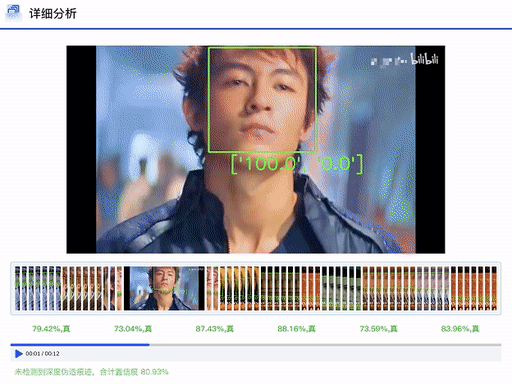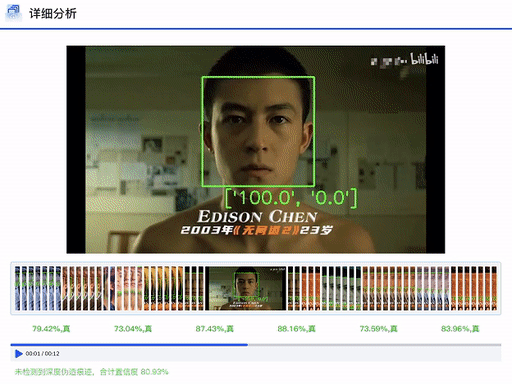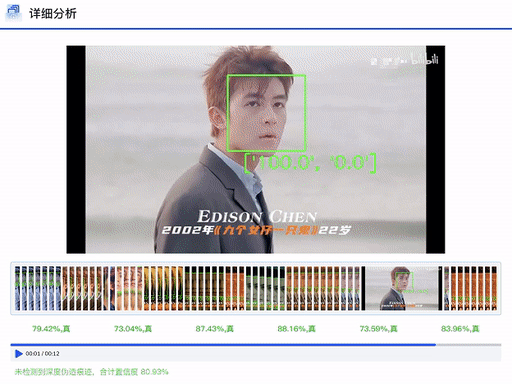
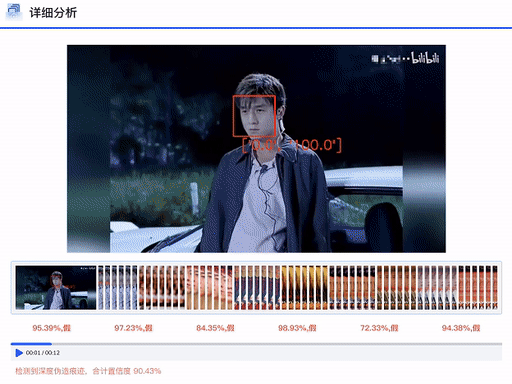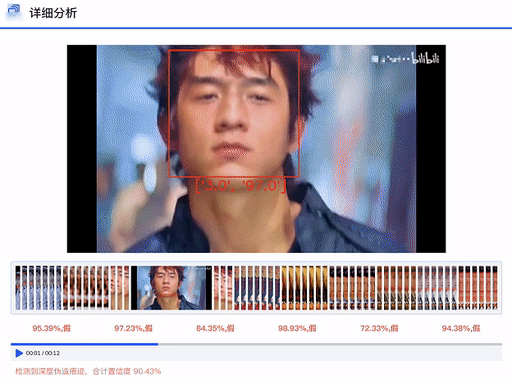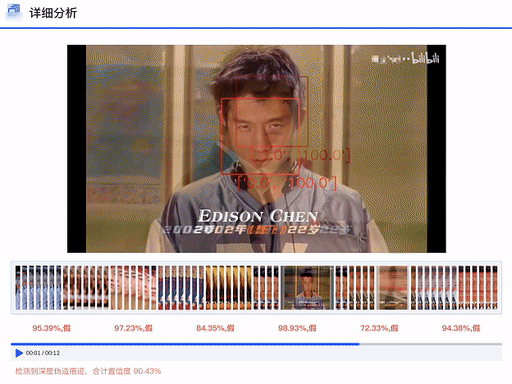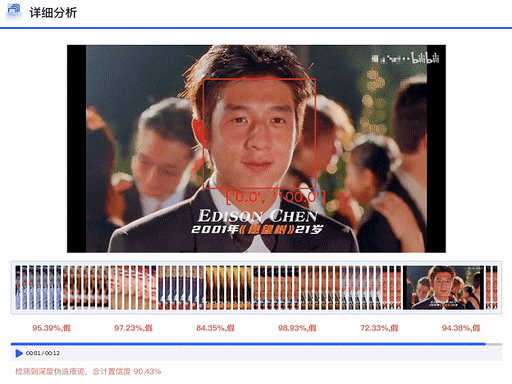
DFscan平台视频检测结果展示(注:左边置信度越大视频帧越真实)
【DFscan检测能力】
DFscan具有业内领先的真伪检出能力。团队从多个人脸替换的代表性数据集(包括FF++,DFDC,Celeb-DF等)的测试集中随机选取了2万张图像,组成了一个复杂的测试集,对DFscan与多个知名开源模型的检测能力进行对比。实验结果如下图所示,相比于现有的开源检测模型,DFscan在开源数据集上展现出领先的检测性能。
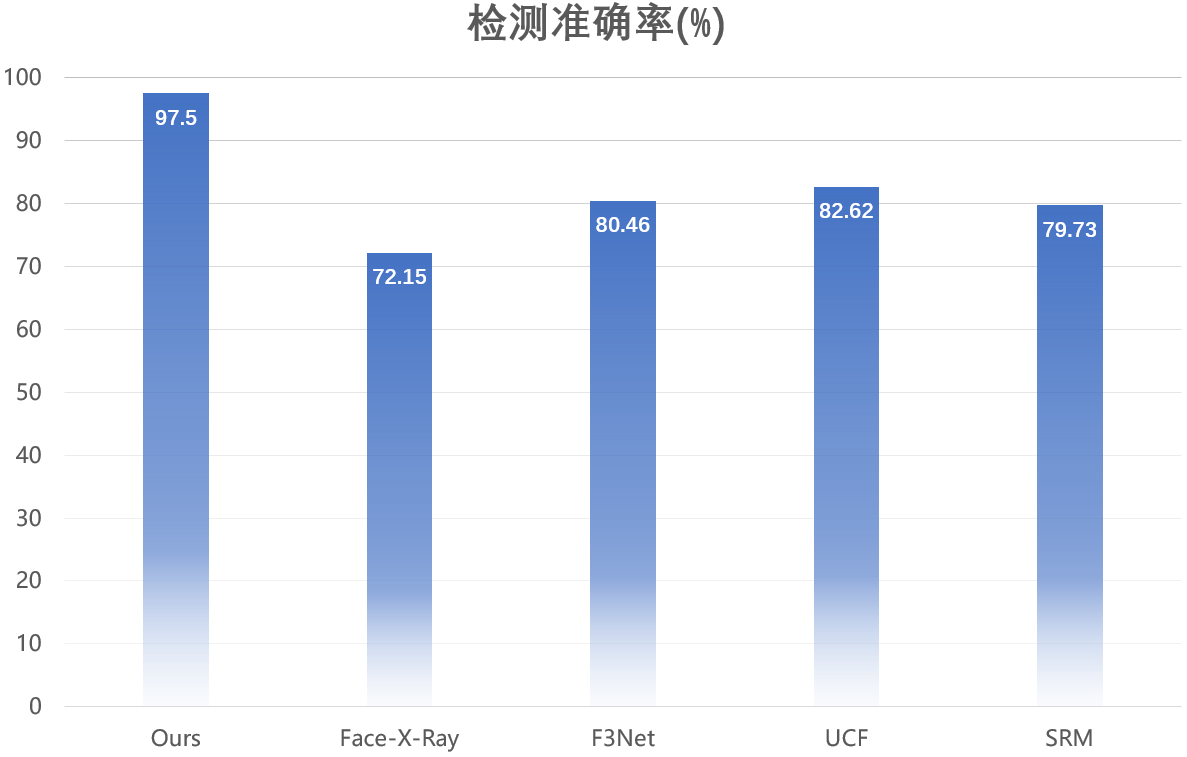
DFscan与知名开源检测模型的性能对比
为了进一步评估DFscan对于不同伪造类型的检测能力,团队对当前视觉AIGC领域最为火热的生成模型合成的图像/视频展开伪造检测测试,这些生成模型包括基于生成对抗网络的StyleGAN,基于扩散模型的文生图大模型Stable Diffusion和Midjourney,以及OpenAI最新的热门文生视频大模型Sora。评估结果如下图所示,DFscan面对多种图像/视频生成模型都取得较高的检测性能,平均准确率大于90%。
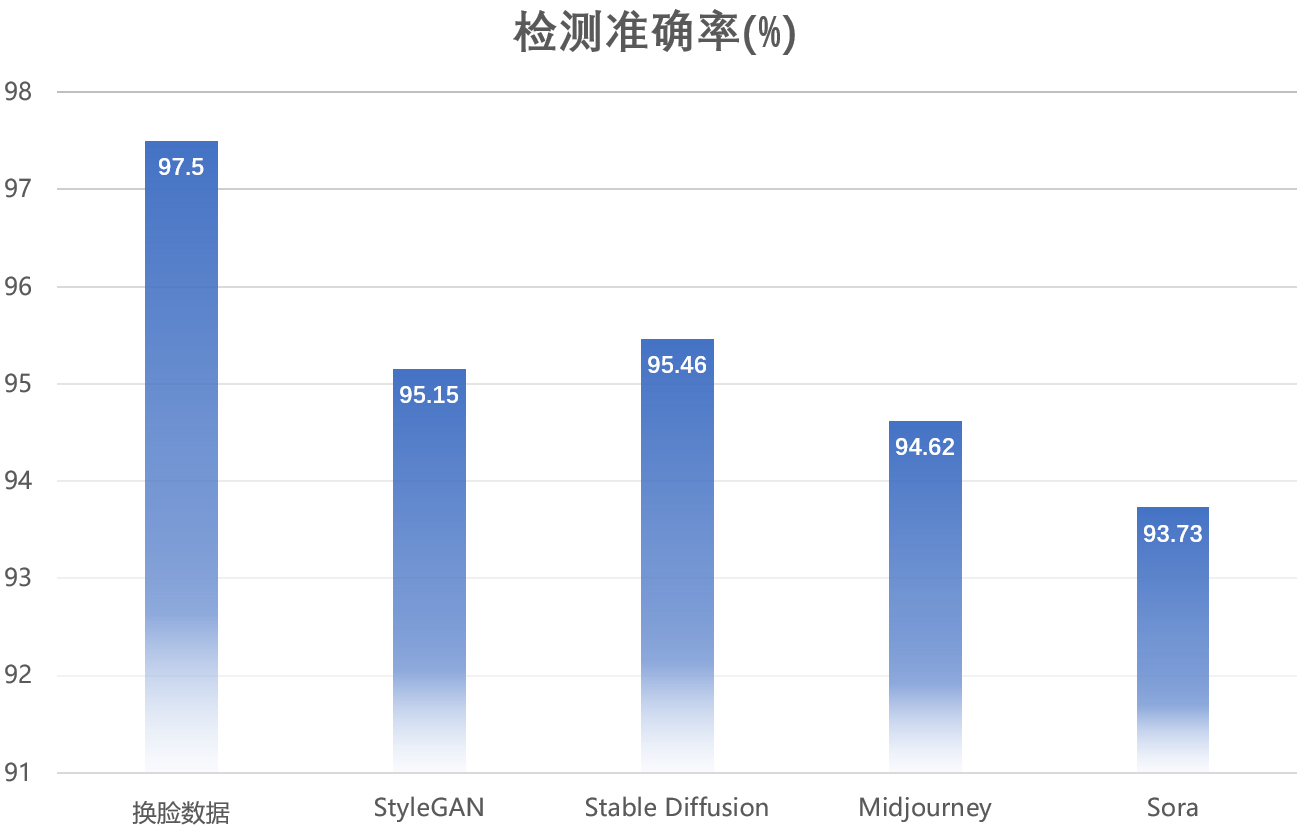
DFscan针对代表性生成算法的检测能力
二、未来规划
生成式人工智能在社会的各个层面展现出了其创新潜力,在赋予人们生活便捷性的同时,其安全性问题亦引起了广泛关注。在此背景下,浙江大学区块链与数据安全全国重点实验室的大模型数据安全团队致力于深度合成内容安全的研究,已成功构建包含千万级伪造内容的数据底座,并成功研发及复现了数十余种深度合成算法。团队持续推进视觉深度伪造检测平台的场景化应用,为AI安全领域的研究与应用提供了有力支持。
鉴于视频深度伪造技术的持续演进,DFscan亦将不断提升其检测能力与展现形式,以满足用户日益增长的需求并应对未来的技术挑战。首先,团队将持续扩充数据底座,迭代更新检测技术,以实现伪造特征的更精准定位和识别,从而提高对DALL·E3、Sora等最新视频图像生成模型的检测准确率。其次,团队将致力于提升对抗场景下的检测鲁棒性,以应对各种形式的视频图像伪造攻击。此外,优化检测结果的呈现形式,提升检测结果的解释性,使用户能够更直观地理解检测结果与检测逻辑,进而提升平台的使用体验。最后,本平台将积极拓展适配场景,以满足不同用户的多样化需求。
展望未来,DFscan将依托浙江大学区块链与数据安全全国重点实验室的雄厚实力,积极与社会各界开展深入的合作与交流。我们诚挚邀请各界相关业务人员通过邮箱联系我们,获取测试账号,直接体验本平台的视频伪造检测等功能。对于有自动化部署需求的用户,我们可提供API接口,实现远程调用。同时,我们亦欢迎企业机构提出特定业务需求,我们将提供针对特定业务场景的定制化合成视频图像检测服务。此外,我们热切期待各界技术人员与安全研究者对本平台提出宝贵意见,并诚挚邀请高校、研究机构以及产业界与我们开展科研与产学研转化等方面的深度合作,共同为生成式人工智能的安全发展贡献力量。如有任何合作意向或建议,请通过DFscanzju@outlook.com与我们联系。
—————————————————————————————————
浙江大学区块链与数据安全全国重点实验室于2022年11月正式获得国家科技部批准成立。实验室由陈纯院士领衔担任主任,聚焦区块链与数据安全国际科技前沿,以实现高水平科技自立自强和打造具有世界一流的战略科技力量为己任,围绕产学研一体融合,开展系统性创新性科技攻关。实验室的研究方向主要包括区块链技术与平台、区块链监管监测、智能合约与分布式软件、数据要素安全与隐私计算、AI数据安全与认知对抗、AI原生数据处理系统、网络数据治理、智能网联车数据安全、可信数据存储与计算技术等。
浙江大学区块链与数据安全全国重点实验室大模型数据安全团队由常务副主任、计算机学院院长任奎教授牵头,在科技部科技创新2030-“新一代人工智能”重大项目、国家重点研发计划项目、国家自然科学基金委区域创新发展联合基金重点项目、浙江省领军型创新创业团队项目、浙江省重点研发项目、浙江省领雁计划项目、浙江省自然科学基金重大项目等多个国家级/省部级项目的支持下,面向大模型数据,研究数据安全与数据隐私基础理论,构建大模型数据安全评测平台和安全组件,为建设大模型数据安全生态提供理论支撑、合规检验及安全加固服务,保障大模型的训练、部署及使用的全流程数据安全。