
近期,浙江大学网络空间安全学院在网络与通信安全方向取得新成果。浙大网安团队联合上海交通大学和美国罗格斯大学研究团队,聚焦语音数据隐私泄露风险,开展语音身份去识别化研究,共同发表的最新研究成果“基于对抗样本的非侵入自适应说话人去识别化”获移动计算领域国际顶级会议ACM MobiCom 2022最佳海报展示提名奖(Best Poster Runner-up Award),克服了语音服务功用和身份隐私保护的困境。
MobiCom是ACM组织在通信网络领域的旗舰性会议,也是中国计算机学会推荐的A类国际会议。
基于对抗样本的非侵入自适应说话人去识别化
题目:A Non-intrusive and Adaptive Speaker De-Identification Scheme Using Adversarial Examples
作者:Meng Chen, Li Lu, Jiadi Yu, Yingying Chen, Zhongjie Ba, Feng Lin, Kui Ren
主要内容:
智能语音服务为用户提供智能化交互体验的同时,语音数据公布的隐私风险引起了广泛关注。微软、谷歌等科技巨头长期收集和存储用户语音,苹果和亚马逊等语音供应商频频被曝窃听用户谈话。用户的身份隐私面临着各种潜在威胁,特别是许多专业的自动说话人辨认工具能够仅从数十秒语音中轻易揭露用户的声纹特征,并用于精准用户画像、定向广告投放甚至个体身份伪造等。面对语音服务功能和个人身份隐私之间的困境,现有的说话人去识别化研究遵循语音转换和语音合成的范式消除语音中的个体特征同时保留文本内容,但直接修改和重新合成会导致声纹非一致性和语音信号失真,极大影响语音服务的功能尤其是人类参与者的听觉体验。
研究团队从平衡语音服务功能和个人身份隐私的全新视角出发,提出一种基于对抗样本的非侵入、自适应说话人去识别化系统。该系统运行在用户端,在源语音离开本地之前通过对抗扰动注入的方式实现语音身份转换。利用对抗样本对神经网络模型的强大攻击性和人耳难以感知的隐蔽性,去识别化的语音能够隐藏用户的原始身份信息不被自动系统辩别,同时保留完整的语义信息以及一致声纹和较高的音质。
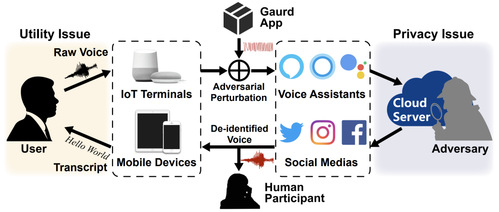
该系统将对抗样本转化为一种身份去识别化工具,在保护用户身份同时保留文本信息并兼顾人耳听感。具体而言,该系统通过预训练的嵌入码级别条件变分自编码器,按需采样多样的目标说话人身份嵌入码;通过输入相关的对抗扰动生成方式,实现任意对任意的说话人身份变换,从而自适应地躲避半知情和知情攻击的身份检测;此外,该系统利用声学掩蔽效应将对抗扰动隐藏在不可听域以提升匿名化语音的音质,提供非侵入式的用户体验。
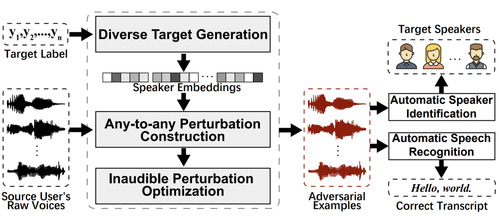
通过对50个说话人的语料进行实验,表明该系统针对4个主流自动说话人识别模型的平均去识别化成功率达到98.2%,同时去识别化处理后的语音经过自动语音识别仅损失了5%的字错率,表明该系统能够有效保护语音身份隐私同时保留语义完整性。更重要的是,实验结果表明去识别化语音依然保持4.38的客观语音感知质量(PESQ)和4.56的平均主观评分(MOS),同时针对半知情的扰动破坏和知情的说话人重识别表现出较高的抗攻击能力。因此该系统有望应用于即时通讯和社交媒体等交互场景下的语音隐私保护。