
近期,浙江大学网络空间安全学院在数据交易估值方向取得新成果。团队深挖数据估值技术,开展Shapley值计算研究,两项最新的研究工作“动态Shapley值计算”与“近似Shapley值的高效抽样方法”分别被数据库领域国际顶级会议ICDE 2023和 SIGMOD 2023接收。
ICDE和SIGMOD分别是IEEE和ACM在数据库领域的旗舰会议,也是中国计算机学会推荐的A类国际会议。
数据是21世纪的石油,成为经济发展的新生产要素。数据市场是促进数据交易的平台,是一种公开、透明、商业化的新型数据共享形式。数据市场将数据消费者与合适的数据供应商进行匹配,挖掘出数据应有的商业价值。数据定价是新兴数据市场领域中的重要课题之一。Shapley值来源于合作博弈论,得益于其公平性,近来被广泛应用于数据估值,即量化训练数据对于机器学习模型中的贡献。然而,由于Shapley的组合性质,Shapley值的精确计算是 #P-hard问题。因此,如何提升Shapley值近似计算效率成为一个亟需突破的关键问题。
一、动态Shapley值计算
1.题目
Dynamic Shapley Value Computation
2.作者
Jiayao Zhang, Haocheng Xia, Qiheng Sun, Jinfei Liu, Li Xiong, Jian Pei, Kui Ren
3.主要内容
最近推出的隐私立法,例如通用数据保护条例 (GDPR) 和加州消费者隐私法案 (CCPA),要求个人有权从组织中删除其个人数据。因此,数据市场中的组织需要经常重新训练模型以适应数据所有者的此类要求,并高效更新Shapley值以调整其估值补偿。然而,现有的相关研究都是对静态数据建模,当数据拥有者的加入或退出使数据集动态变化时只能从头计算,无法有效利用在原数据集上评估的Shapley值,带来大量计算开销,严重影响更新效率。为解决在数据动态变化时如何高效更新Shapley值的问题,本文提出了多种动态Shapley值计算方法。
一方面,本文对数据集动态变化前后的效用方程进行压缩分解,尽可能保留有效信息到下一次计算过程中,避免冗余计算;同时将新Shapley值划分为原值和改变量两部分,将求解新Shapley值的问题转换为求解Shapley值变化量的问题,由于变化量的分布范围相对较小,能够以更少的计算量使近似的新Shapley值达到指定精度。另一方面,本文基于数据相似度关联动态数据与原数据的Shapley值,基于数据分布分析动态数据对原数据Shapley值的波动影响,以及新数据与原数据各自Shapley值之间的关联关系,通过模型拟合,进而快速更新Shapley值。
二、近似Shapley值的高效抽样方法
1.题目
Efficient Sampling Approaches to Shapley Value Approximation
2.作者
Jiayao Zhang, Qiheng Sun, Jinfei Liu, Li Xiong, Jian Pei, Kui Ren
3.主要内容
Shapley值提供了一种独特的方式来公平地评估每个参与者在联盟中的贡献,并且得到了多种应用。现有Shapley值抽样近似计算方法大部分基于原始的边际贡献,由于边际贡献值定义为特定参与者在指定合作联盟中存在与否的效用差异,一个边际贡献值只能用于特定参与者的Shapley值计算,无法被重用。这意味着基于边际贡献的算法需要大量的样本和多次联盟效用评估才能达到高质量的近似。为了解决这个问题,本文基于Shapley原始定义提出了一种新型效用差异,名为互补贡献。互补贡献的每个样本都可用于所有参与者的Shapley值计算过程中,因此可以直接被所有参与者重用。
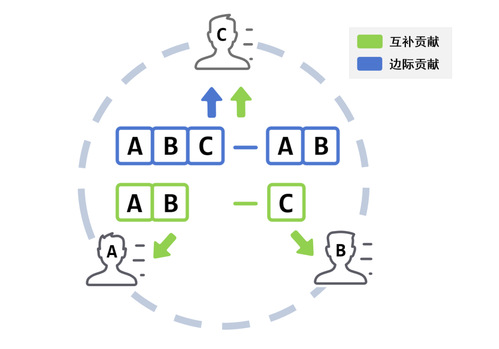
图1 互补贡献与边际贡献
本文首先设计了基于互补贡献的朴素分层抽样近似计算算法。由于不同长度联盟的对立贡献在Shapley值计算中权值相同,本文为降低抽样方差,基于内曼分配设计一种二阶段的分层抽样方法来近似计算所有参与者Shapley值,该方法在第一阶段随机抽样不同长度的互补贡献,并在第二阶段根据抽样值极大似然分配剩余抽样次数以近似计算所有参与者Shapley值。为了进一步提高效率,本文结合经验伯恩斯坦界提出动态互补贡献样本分配方法来提升抽样性能。