
在日前召开的国际移动计算和感知领域顶级会议ACM SenSys’21上,浙江大学网络空间安全研究中心韩劲松教授、林峰研究员和任奎教授团队有2篇论文正式发表,均荣获会议最佳论文奖提名(Best Paper Candidate)。SenSys会议全称为The ACM Conference on Embedded Networked Sensor Systems,由美国计算机协会(ACM)主办,为Csranking里移动计算领域的三大国际顶级学术会议之一,本届会议录用率仅为17.9%。获奖的两篇论文代表了团队在利用WiFi、毫米波等射频信号进行无线感知方面的最新进展。其中,OneFi工作对小样本标注下的WiFi手势识别系统设计提出新的解决方案。Wavoice工作则将毫米波与语音结合,实现抗干扰强且识别距离远的多模态语音识别系统。以下是两篇论文的简介:
1. OneFi: One-Shot Recognition for Unseen Gesture via COTS WiFi。
基于WiFi信号进行手势识别的技术,因其具有无接触、隐私泄露少、以及普适性强等优点,成为目前研究的热点。然而,传统的WiFi手势识别系统需要用户采集大量数据来注册新手势,且一旦引入新手势,则整个识别模型需要重新训练。巨大的数据采集开销和模型训练开销,使得系统扩展性严重受限。OneFi是一种新的WiFi手势识别框架,在此框架下,用户对于新动作仅需要一条训练数据即可完成注册,从而解决了小样本标注条件下采用深度学习方法进行WiFi手势识别的难题,极大地节省了采集和训练开销,在智慧医疗、智能家居等领域具有较大的潜在应用价值。
基于相似性检验的小样本识别框架:OneFi设计的小样本识别框架,针对新的手势,仅需微调一个加权矩阵,即可完成对新动作的识别,从而省去了大量数据采集和模型训练的开销。具体而言,该框架通过在原有数据集上训练一个特征提取器,从而获取WiFi手势相关的先验知识。而微调过后的加权矩阵可以对新手势给出相似性得分,从而对新手势进行准确的识别。该框架有效减小了适应新手势需要的开销。
基于自注意力机制的骨干网络:由于WiFi手势信号包含时序信息,因此传统的识别系统常使用长短期记忆网络作为骨干网络。然而,长短期记忆网络由于其串行处理的本质,导致训练速度慢,开销大。针对这个问题,OneFi提出使用自注意力机制来取代长短期记忆网络,作为特征提取器的骨干网络。由于自注意力模块能够并行处理时序信息,因此大大减小了特征提取器的训练开销。
基于信号建模的数据增强方案:针对先验信息不足的问题,OneFi设计了一种数据增强方案。由于WiFi的CSI信号与图像信息在语义上有着本质的不同,因此在图像识别领域常用的放缩、旋转、拉伸等数据增强方案,在WiFi信号上并不适用。OneFi针对WiFi信号,创新性地设计了一种基于信号建模的数据增强方案,通过对WiFi数据进行处理,提取手势动作的速度信息,并在速度域上进行旋转操作,从而可以合成大量的虚拟手势。在先验信息不足的情况下,合成的虚拟手势能够有效丰富先验信息,从而提高模型的识别准确率。
2. Wavoice: A Noise-resistant Multi-modal Speech Recognition System Fusing mmWave and Audio Signals。
Wavoice基于毫米波雷达和麦克风各自对语音发声的感知, 通过融合网络的设计来结合两种模态的写作互补,利用毫米波对环境噪声不敏感和语音对运动干扰不敏感的特性,实现了一种多模态的抗噪声干扰语音识别系统。未来在智慧家庭,智慧城市,车载语音识别都有广泛的应用前景。
传统的基于麦克风的语音交互系统容易受噪音或口罩等遮挡的影响,从而使识别语音内容的准确率下降,另外,传统语音交互系统的识别距离受限,识别距离往往不超过5米,影响语音交互的用户体验。因此,我们设计了Wavoice来解决以上问题,并提出新的语音相关性模型和融合网络来对两种同源异质信号进行跨模态融合,解决系统实现中的挑战。
恶劣条件下如何检测语音互动:我们研究了毫米波感知人声的模型与麦克风感知人声的模型,建立了两者之间的相关性模型,发现两者具有相同的频率分量。基于此,我们设计了自适应阈值法来检测相乘产生的低频分量,以达到高精度的语音识别检测。
如何融合毫米波与语音:我们基于注意力机制设计了一个融合网络(图1)以生成融合特征。融合网络实现了两个模态之间的合作与交互,语音模态会向毫米波模态提供有用的声音信息,而毫米波模态同时也会向语音提供有关喉咙振动的特征,弥补因为噪音受损的语音信息。
多人条件下如何判断标定用户信号:为了从周围干扰用户中筛选出目标用户信号,我们对之前观察发现到的乘积分量提取Liner Predictive Coding(LPC)特征。该特征不仅计算速度快并且能挖掘出不同信号间的差异,然后,将该LPC特征输入至OC-SVM以判断信号是否来自用户。
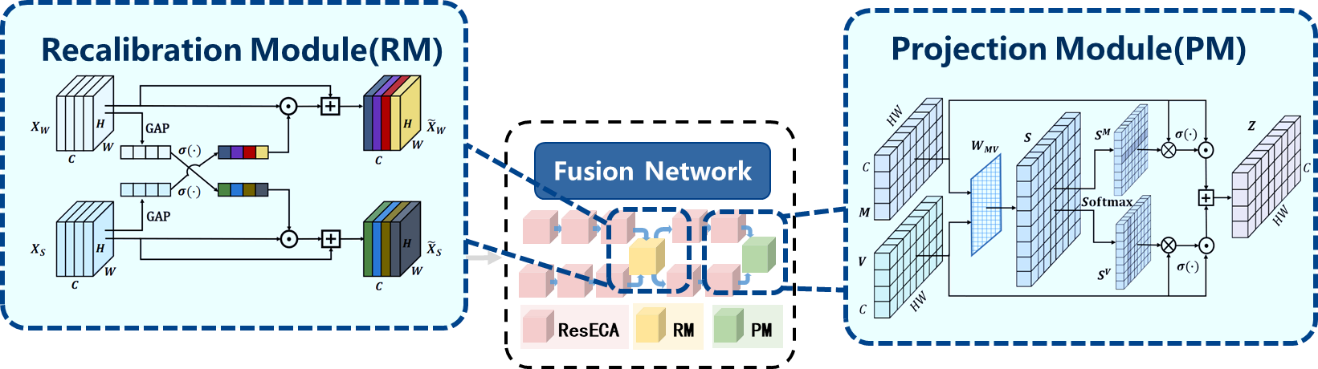
图1 融合网络
实验结果:Wavoice在不同环境和不同条件下进行了全面的评估,并且与当今流行的基于单一麦克风的语音识别系统作为对比。实验结果表示,在高噪音的环境下,Wavoice的字母错误率在1%以内,优于传统语音识别系统至少20倍。系统在不同角度(-60°-60°)和不同距离(1-10米)下依旧保持低于2%的字母错误率,而且在用户运动的情况下,系统依旧能提供高准确的语音识别能力。同时还测试了该系统在车载环境下的识别性能,结果表明即使在毫米波雷达晃动的情况下,系统的字母错误率稳定在0.5%左右。这说明该系统能够在各种恶劣环境下提供稳定又高精度的语音识别。
[1] Xiao R, Liu J, Han J, Ren K. OneFi: One-Shot Recognition for Unseen Gesture via COTS WiFi. InProceedings of the 19th ACM Conference on Embedded Networked Sensor Systems 2021 Nov 15 (pp. 206-219).
[2] Liu T, Gao M, Lin F, Wang C, Ba Z, Han J, Xu W, Ren K. Wavoice: A Noise-resistant Multi-modal Speech Recognition System Fusing mmWave and Audio Signals. InProceedings of the 19th ACM Conference on Embedded Networked Sensor Systems 2021 Nov 15 (pp. 97-110).
1. OneFi: One-Shot Recognition for Unseen Gesture via COTS WiFi。
基于WiFi信号进行手势识别的技术,因其具有无接触、隐私泄露少、以及普适性强等优点,成为目前研究的热点。然而,传统的WiFi手势识别系统需要用户采集大量数据来注册新手势,且一旦引入新手势,则整个识别模型需要重新训练。巨大的数据采集开销和模型训练开销,使得系统扩展性严重受限。OneFi是一种新的WiFi手势识别框架,在此框架下,用户对于新动作仅需要一条训练数据即可完成注册,从而解决了小样本标注条件下采用深度学习方法进行WiFi手势识别的难题,极大地节省了采集和训练开销,在智慧医疗、智能家居等领域具有较大的潜在应用价值。
基于相似性检验的小样本识别框架:OneFi设计的小样本识别框架,针对新的手势,仅需微调一个加权矩阵,即可完成对新动作的识别,从而省去了大量数据采集和模型训练的开销。具体而言,该框架通过在原有数据集上训练一个特征提取器,从而获取WiFi手势相关的先验知识。而微调过后的加权矩阵可以对新手势给出相似性得分,从而对新手势进行准确的识别。该框架有效减小了适应新手势需要的开销。
基于自注意力机制的骨干网络:由于WiFi手势信号包含时序信息,因此传统的识别系统常使用长短期记忆网络作为骨干网络。然而,长短期记忆网络由于其串行处理的本质,导致训练速度慢,开销大。针对这个问题,OneFi提出使用自注意力机制来取代长短期记忆网络,作为特征提取器的骨干网络。由于自注意力模块能够并行处理时序信息,因此大大减小了特征提取器的训练开销。
基于信号建模的数据增强方案:针对先验信息不足的问题,OneFi设计了一种数据增强方案。由于WiFi的CSI信号与图像信息在语义上有着本质的不同,因此在图像识别领域常用的放缩、旋转、拉伸等数据增强方案,在WiFi信号上并不适用。OneFi针对WiFi信号,创新性地设计了一种基于信号建模的数据增强方案,通过对WiFi数据进行处理,提取手势动作的速度信息,并在速度域上进行旋转操作,从而可以合成大量的虚拟手势。在先验信息不足的情况下,合成的虚拟手势能够有效丰富先验信息,从而提高模型的识别准确率。
2. Wavoice: A Noise-resistant Multi-modal Speech Recognition System Fusing mmWave and Audio Signals。
Wavoice基于毫米波雷达和麦克风各自对语音发声的感知, 通过融合网络的设计来结合两种模态的写作互补,利用毫米波对环境噪声不敏感和语音对运动干扰不敏感的特性,实现了一种多模态的抗噪声干扰语音识别系统。未来在智慧家庭,智慧城市,车载语音识别都有广泛的应用前景。
传统的基于麦克风的语音交互系统容易受噪音或口罩等遮挡的影响,从而使识别语音内容的准确率下降,另外,传统语音交互系统的识别距离受限,识别距离往往不超过5米,影响语音交互的用户体验。因此,我们设计了Wavoice来解决以上问题,并提出新的语音相关性模型和融合网络来对两种同源异质信号进行跨模态融合,解决系统实现中的挑战。
恶劣条件下如何检测语音互动:我们研究了毫米波感知人声的模型与麦克风感知人声的模型,建立了两者之间的相关性模型,发现两者具有相同的频率分量。基于此,我们设计了自适应阈值法来检测相乘产生的低频分量,以达到高精度的语音识别检测。
如何融合毫米波与语音:我们基于注意力机制设计了一个融合网络(图1)以生成融合特征。融合网络实现了两个模态之间的合作与交互,语音模态会向毫米波模态提供有用的声音信息,而毫米波模态同时也会向语音提供有关喉咙振动的特征,弥补因为噪音受损的语音信息。
多人条件下如何判断标定用户信号:为了从周围干扰用户中筛选出目标用户信号,我们对之前观察发现到的乘积分量提取Liner Predictive Coding(LPC)特征。该特征不仅计算速度快并且能挖掘出不同信号间的差异,然后,将该LPC特征输入至OC-SVM以判断信号是否来自用户。
图1 融合网络
实验结果:Wavoice在不同环境和不同条件下进行了全面的评估,并且与当今流行的基于单一麦克风的语音识别系统作为对比。实验结果表示,在高噪音的环境下,Wavoice的字母错误率在1%以内,优于传统语音识别系统至少20倍。系统在不同角度(-60°-60°)和不同距离(1-10米)下依旧保持低于2%的字母错误率,而且在用户运动的情况下,系统依旧能提供高准确的语音识别能力。同时还测试了该系统在车载环境下的识别性能,结果表明即使在毫米波雷达晃动的情况下,系统的字母错误率稳定在0.5%左右。这说明该系统能够在各种恶劣环境下提供稳定又高精度的语音识别。
[1] Xiao R, Liu J, Han J, Ren K. OneFi: One-Shot Recognition for Unseen Gesture via COTS WiFi. InProceedings of the 19th ACM Conference on Embedded Networked Sensor Systems 2021 Nov 15 (pp. 206-219).
[2] Liu T, Gao M, Lin F, Wang C, Ba Z, Han J, Xu W, Ren K. Wavoice: A Noise-resistant Multi-modal Speech Recognition System Fusing mmWave and Audio Signals. InProceedings of the 19th ACM Conference on Embedded Networked Sensor Systems 2021 Nov 15 (pp. 97-110).